Skeleton-Based Action Recognition with Shift Graph Convolutional Network
CVPR 2020
Ke Cheng1,2, Yifan Zhang1,2∗ , Xiangyu He1,2, Weihan Chen1,2, Jian Cheng1,2,3, Hanqing Lu1,2 1NLPR & AIRIA, Institute of Automation, Chinese Academy of Sciences 2School of Artificial Intelligence, University of Chinese Academy of Sciences 3CAS Center for Excellence in Brain Science and Intelligence Technology
Introduction
기존 GCN 기반 행위 인식 메서드는 다음과 같은 두 가지 한계를 가진다.
- The computational complexity is too heavy. For example, ST-GCN [34] costs 16.2 GFLOPs1 for one action sample.
- The receptive fields of both spatial graph and temporal graph are pre-defined heuristically even if the learnable adjacent matrix.
이를 극복하기 위해 Shift-CNN의 shift연산을 도입하여 연산량을 낮출뿐 아니라, 적응형 shift 를 적용하여 receptive fileds도 dynamic 하게 확장시킨다.
Method
GCN 사이사이에서 shift operation을 적용시킨다.
Spatial
1. Local shift graph convolution
각 관절(joint)의 feature를 그룹으로 분할하여 인접노드들과 교환한다.
아래 (a)의 예시처럼, Node 1의 이웃노드는 Node 2로 총 $Adj=1$개이며 feature는 총 $M=20$개의 채널을 가진다.
논문의 정의에 따라, 한 그룹의 채널수는 $rounddown(\frac{M}{Adj+ 1})$ --> $ rounddown(\frac{20}{1+1}) = 10 $ 이므로 총 2개의 그룹으로 나눠진다.

그런데, 최종결과물의 Node 3을 보면 마지막 1/4 조각이 유실되었다. 이는 각각의 노드가 서로 다른 갯수의 인접노드를 가지는 데서 오는 한계점이다. 뿐만 아니라 최근 연구에 따르면 인접노드들만 고려하는 것은 최적의 성능을 얻지 못한다. ( e.g., 박수치기 행위에 주요 부위인 왼손과 오른손은 신체구조상 직접적인 연관이 없다).
2. Non-Local shift graph convolution

Local-shift의 데이터 유실과 global-connection부족을 개선하기 위해 모든 관절 사이의 데이터를 shift 한다.
$\mathbf{F} \in \mathcal{R}^{N*C}$ 일 때, $i^{th}$ 채널은 $ i \mathbf{mod} N $만큼 shift된다. 예를 들어 1번 노드의 경우, 1%7 =1 2%7= 2, 3%7 =3, ... 7%7=1 에서 끌어온다. 때문에 1번과 7번은 그대로다.
이 방법은 관절 사이의 모든 관계가 동일한 가중치를 가진다. 하지만 각 관절들은 행위별로 다른 가중치를 가지므로 이를 극복하기 위해 learnable mask를 하나 추가해준다.
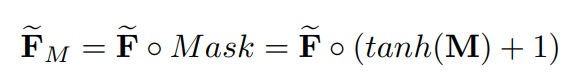
Temporal
1. Naive shift
TSM과 유사하게 각각의 채널을 $2*u +1$개의 그룹으로 나눈 후 shift한다. 마찬가지로 truncate되어 생긴 빈 공간은 0으로 채워진다.
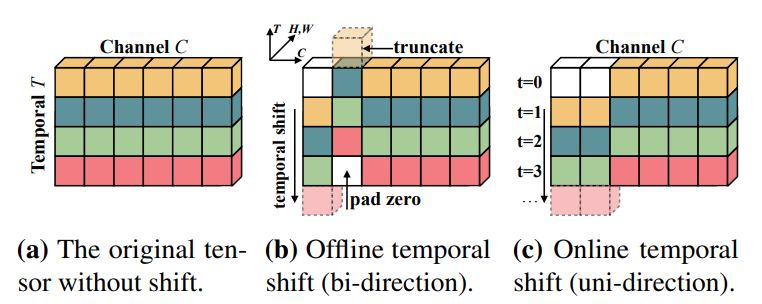
2. Adaptive shift
Naive shifting의 경우 $u$rk heuristic하게 결정되며 다음과같은 단점이 있다.
- Different layers need diverse temporal receptive fields in video classification tasks.
- Different datasets may need different temporal receptive fields.
따라서 각 채널마다 learnable shift parameter를 두어 데이터로부터 능동적으로 학습하게 한다.
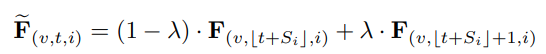

원래대로라면 shift는 discrete 연산이지만 실수에서도 동작할 수 있도록 $\lambda$를 조절해준다. 이로써 모든 실수에 대해 $F$가 동작하므로 연속적/미분가능함으로 딥러닝 학습이 가능해진다.
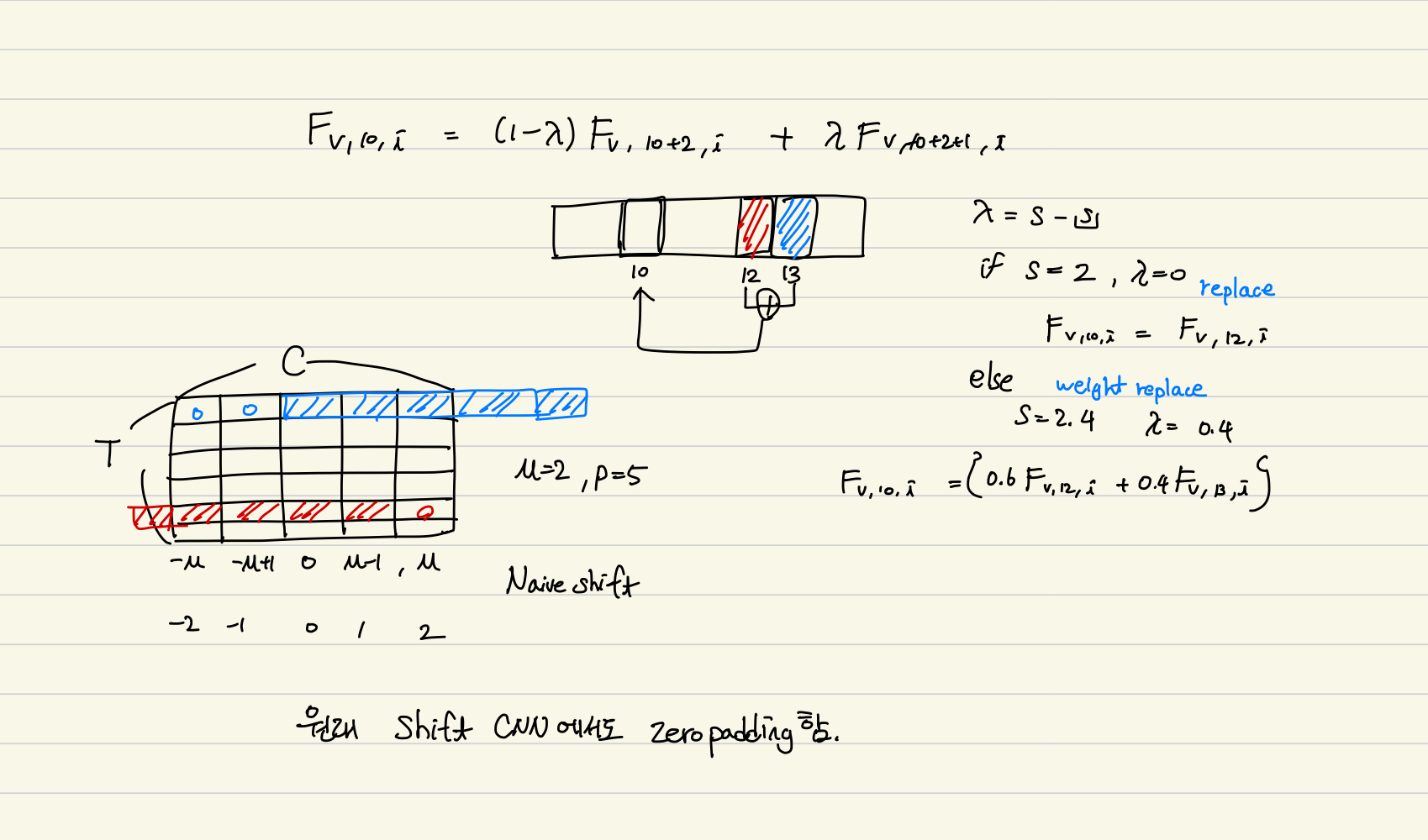
----------------------------------
Model
ST-GCN을 Backbone model로 쓴다.
기존 spatial graph convolution을 spatial shift & point-wise conv로 교체하여 수행한다.
Experimetn
Data
기존 ST-GCN처럼 pre_normalization (Trainslation, Rotation, Scaling)을 수행함.
'Graph Action Recognition' 카테고리의 다른 글
| ResGCN (0) | 2021.03.11 |
|---|